type
status
date
slug
summary
tags
category
icon
password
这里写文章的前言:
Spark3.0.1合并Iceberg的小文件
📝 Iceberg小文件处理
Spark3.0.1
Spark3.0.1版本的sql执行
参数说明:
- 如果有 catalog 的设置的话,在system前面加上 catalog. (catalog是你具体的catalog名字,比如spark_hadoop)
- ods_bigscreen.o_ecuser_list: 具体的数据库名字和表名字
- TIMESTAMP '2022-09-08 00:00:00.000': 该时间之前的数据进行清除
- 1 是保留的版本数量,比如这里的1就是1
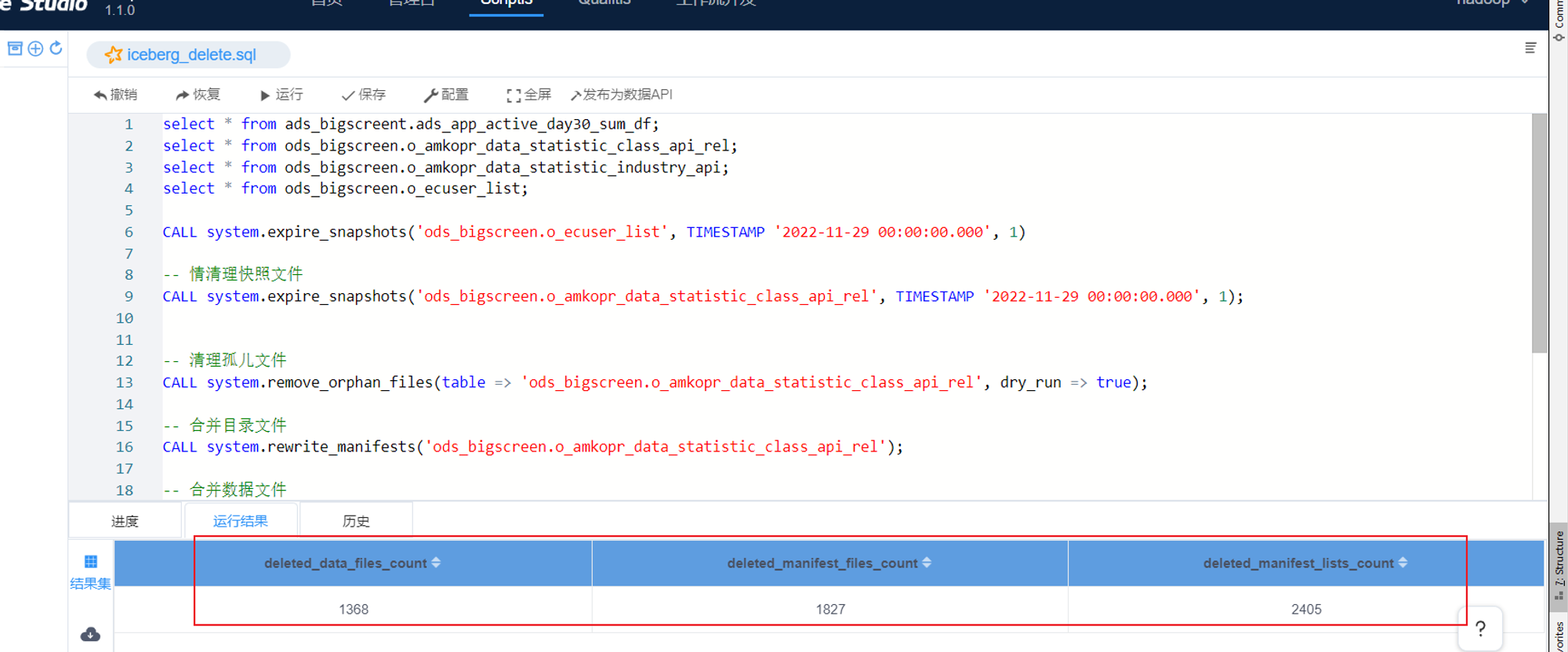
执行结果如下图:
参数解析:
- deleted_data_files_count 删除对应表的data文件夹个数。如果我们的文件格式选择的是 parquet,那么文件是以 .parquet 结尾,比如 00000-0-0eca9076-9c03-4077-baa9-e68769e15c58-00001.parquet 就是一个数据文件。
- deleted_manifest_files_count: 删除元数据metadata文件夹的数据。其里面列出了组成某个快照(snapshot)的数据文件列表。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据的行数等信息。其中列级别的统计信息在 Scan 的时候可以为算子下推提供数据,以便可以过滤掉不必要的文件。每次更新会产生多个清单文件。
- deleted_manifest_lists_count: 清单列表也是元数据文件,其里面存储的是清单文件的列表,每个清单文件占据一行。每行中存储了清单文件的路径、清单文件里面存储数据文件的分区范围、增加了几个数据文件、删除了几个数据文件等信息。这些信息可以用来在查询时提供过滤。清单列表也是 avro 格式进行存储的,所以是以 .avro 后缀结尾的;而且这个文件是以 snap- 开头的,比如 snap-7389540589641972921-1-aa90f6ed-aee2-49c7-a61c-bd13ed411c66.avro,其中 7389540589641972921 这串数字是代表快照 id(snapshot_id)。每次更新都会产生一个清单列表文件。
pySpark进行处理
使用 use 获取 某个数据库的表,然后对这些表进行 合并小文件处理
建表语句
在见表语句上加上对应的参数配置
Property | Description |
write.metadata.delete-after-commit.enabled | 每次表提交后是否删除旧的元数据文件 |
write.metadata.previous-versions-max | 要保留旧的元数据文件数量 |
CREATE TABLE ${CataLog名称}.${库名}.${表名} ( id bigint,
name string) using icebergPARTITIONED BY ( loc string) TBLPROPERTIES ( 'write.metadata.delete-after-commit.enabled'= true, 'write.metadata.previous-versions-max' = 3)🤗 总结归纳
📎 参考文章
有关文章的问题,欢迎您在底部评论区留言,一起交流~